大家應該都有發現,無論是上購物網站或是YouTube、Netflix等影音網站、甚至是社群軟體,他們總是知道你想看什麼,點進去不過一分鐘的時間,其實網站們早已分析好你的喜好,並且忙著計算有什麼相似的內容可以推薦給你,往後瀏覽其他網頁馬上變成相關影片或廣告,這全都仰賴著「協同過濾」技術。
一、協同過濾兩大核心技術
1. 基於用戶的協同過濾:相似的用戶會有相似的喜好
透過計算用戶之間的相似度來推薦內容,當一個用戶的歷史行為與另一個用戶的行為相似時,系統會推薦另一個用戶喜歡的物品。
• 相似度計算:
Ai 和 Bi 代表用戶 A 和 B 對第 i 個物品的評分。範圍在 [-1, 1] 之間,越接近 1 表示相似度越高。
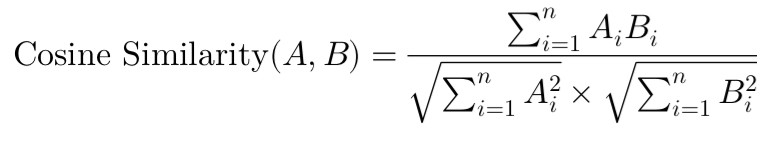
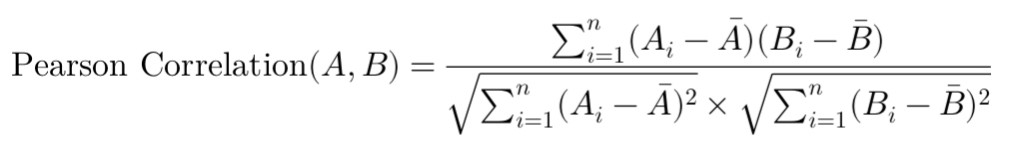
• 缺點:
2. 基於物品的協同過濾:如果一個用戶對某些物品評分較高,推薦與這些物品相似的物品給該用戶
根據物品之間的相似性來推薦,這種方法適合處理具有大量用戶和少量共同行為的情況。
• 相似度計算:和基於用戶的相似度一樣(餘弦、皮爾森係數),區別在於評分向量來自於用戶對物品的評分
• 優點:
• 應用:
二、隱私保護技術:
既然我們點擊什麼都會被電腦偷看、隨時緊盯,那我們的資料安全該何去何從?
1. 差分隱私 (Differential Privacy)
保護個人數據的隱私,同時仍然允許系統從數據集中學習有用的統計信息,在保留總體的同時不泄露個體信息
•如何運作:
向數據中添加隨機分佈的噪聲來保護隱私,即使攻擊者擁有數據庫的大部分信息,也無法準確推斷出單個用戶的數據。
•應用於推薦系統:
向用戶的評分數據或行為數據中加入噪聲,來避免直接暴露用戶的個人偏好或習慣,這樣即使其他人擁有部分數據,也無法還原單個用戶的完整行為。
•缺點:添加噪聲會降低推薦系統的精確度,尤其在數據量較少的情況下,因此平衡隱私和準確度是一個挑戰。
2.聯邦學習 (Federated Learning):
允許不同設備(如手機、電腦等)在不共享數據的情況下共同訓練機器學習模型。在保護用戶隱私的同時,依然能讓系統從不同用戶的數據中學習有效的推薦模式。
•如何運作:
將模型訓練過程分佈到各個用戶的設備上,而不是將數據集中到中央伺服器。
•應用於推薦系統:
使系統能從各用戶的行為中學習推薦模式,而無需收集用戶的數據。
例如:Google 使用聯邦學習來改進手機的輸入法推薦,而不會將每個人的打字記錄發送到中央伺服器。
•缺點:
這些技術讓推薦變得更貼心,隱私也更有保障。所以下次刷到那些完美推薦時,不妨偷偷感謝一下這些默默運作的科技吧。

